The Alchemist's Fallacy
Why the semantic layer isn't an extra layer, and why we keep miscounting the architecture

A few weeks ago I was presenting a data platform architecture. Familiar shape. Bronze for raw ingestion, Silver for cleaned data, Gold for business-ready consumption. On top of that I had drawn a semantic layer. An ontology. A knowledge graph. A way for the data to know what it meant and not just what it was.
A hand went up. “Isn’t that too many layers?”
I agreed with the concern. We already manage lakehouses and warehouses and feature stores and god knows what else, and the last thing anyone wants is another stratum to babysit. I did not have a good answer that day. I mumbled something about metadata and moved on.
I have been thinking about it ever since. We were both wrong. Not about the problem, complexity is real, but about the shape of the solution. The semantic layer is not an extra layer on top of the medallion. It is what Gold becomes when you do Gold properly. We are not adding pancakes to the stack. The top pancake is turning into something else.
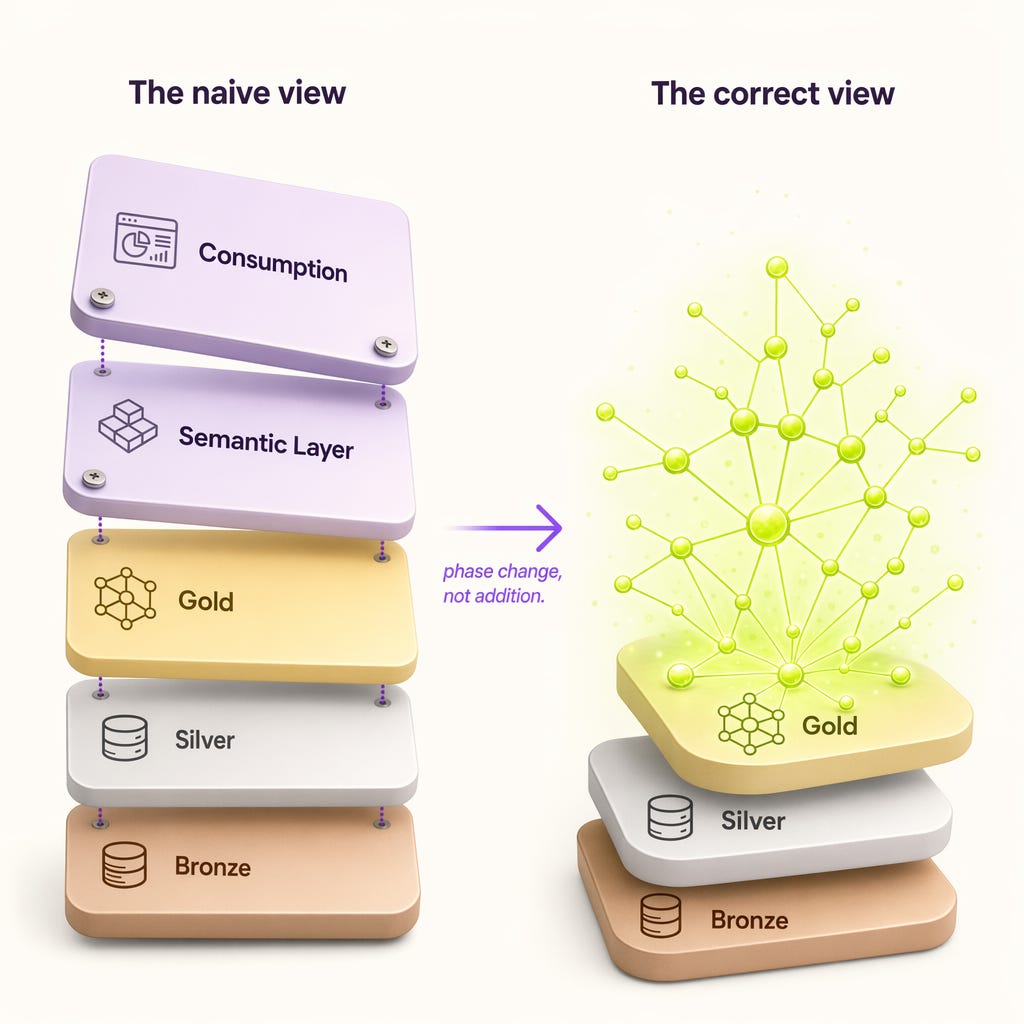
The stack trap
The medallion has become so familiar that we have stopped examining the metaphor. Bronze (raw), Silver (cleaned), Gold (business-ready). It sounds like a refining process. It is. But it also trains us to think additively. Each stage makes the previous stage more of something. More clean. More joined. More aggregated.
That model makes the semantic layer look like a “Gold Plus.” A fourth stage where you take the nice tables and add meaning to them. Map columns to an ontology. Build a graph on the side. Train an AI to interpret the schema. Whatever the move, it feels like overhead.
That feeling is the alchemist’s fallacy. You think you are stacking materials. You are managing states of matter.
The phase change
A separate line of work from Veronika Heimsbakk, the Semantic Medallion, proposes a simple but uncomfortable redesign. Keep the three layers. Redefine what each one delivers.
Bronze — harvest and land
Data lands as-is. No semantics. Just ingestion and storage. This part hasn’t changed in a decade. Connectors pull from APIs, CDC streams, file drops, and write to object storage in their original shape.
# Bronze: nothing fancy. Land the raw payload, preserve provenance.
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
(spark.read.format("json")
.load("s3://landing/crm/customers/2026-05-16/*.json")
.withColumn("_ingested_at", current_timestamp())
.withColumn("_source_system", lit("crm"))
.write.mode("append")
.format("delta")
.save("s3://bronze/crm/customers"))No transformations. No joins. The Bronze layer has one job: if it arrived, we have it.
Silver — structure and identify
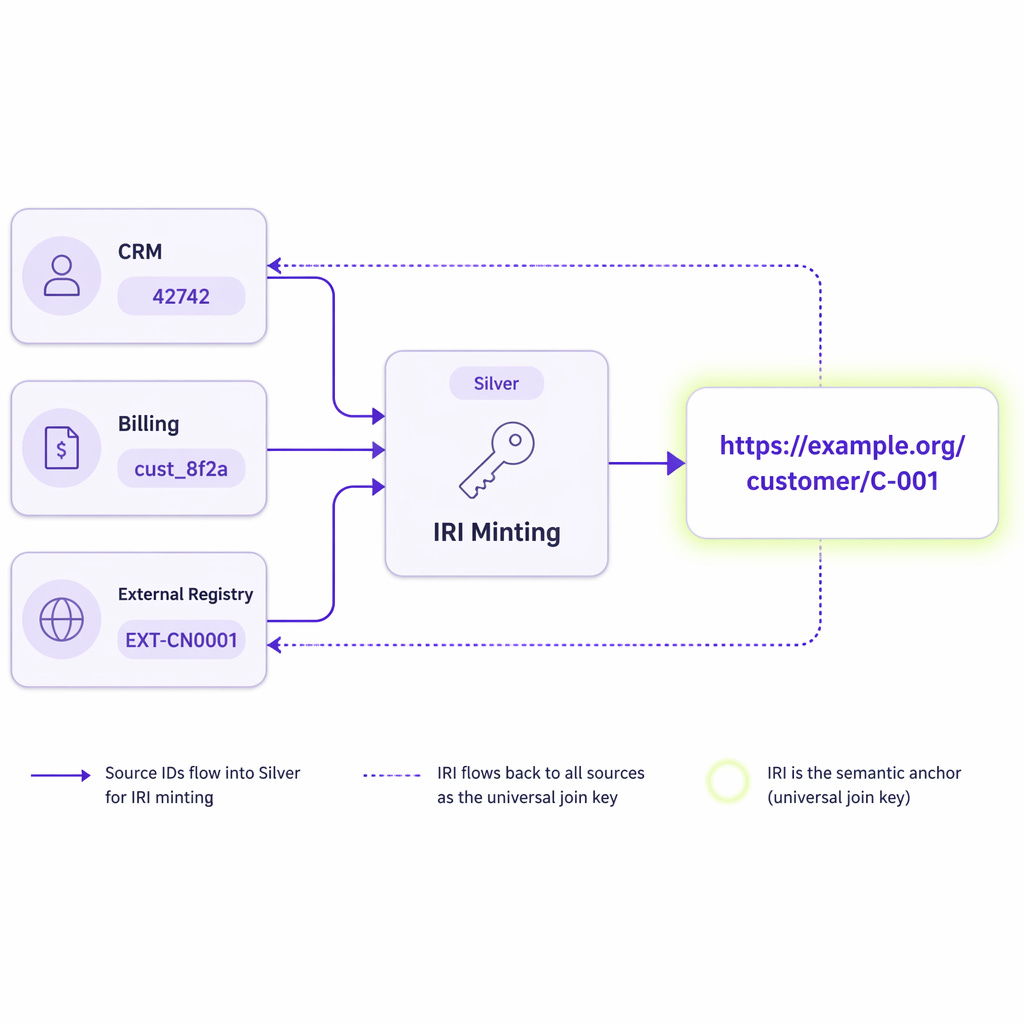
Cleaning and type enforcement happen here, as usual. But there is one extra step, and it is the thing everything downstream depends on. Every entity gets an IRI. An Internationalized Resource Identifier. Not a database auto-increment ID. Not a GUID that means nothing outside the system that produced it. An IRI that identifies the actual thing being described.
A customer is no longer row 42,742 in a CRM table. It is:
https://example.org/customer/C-001That identifier is stable, global, and portable. Mint it once in Silver and use it everywhere downstream.
# Silver: clean, enforce types, and mint stable IRIs.
from pyspark.sql import functions as F
BASE = "https://example.org"
silver_customers = (
bronze_customers
.filter(F.col("customer_id").isNotNull())
.withColumn("customer_id", F.trim(F.col("customer_id")))
.withColumn("email", F.lower(F.col("email")))
# The crucial step: mint an IRI per entity.
.withColumn("iri", F.concat(F.lit(f"{BASE}/customer/"), F.col("customer_id")))
.select("iri", "customer_id", "email", "country", "signup_date")
)
silver_customers.write.format("delta").mode("overwrite").save("s3://silver/customer")The IRI is your join key across systems. Not within one database. Across the whole landscape. The CRM, the billing system, and the external registry can all refer to https://example.org/customer/C-001 and they all mean the same customer. This is the part most teams get wrong by deferring. Mint identifiers late and you will spend a year reconciling them.
Gold — harmonize and publish as ontology-native
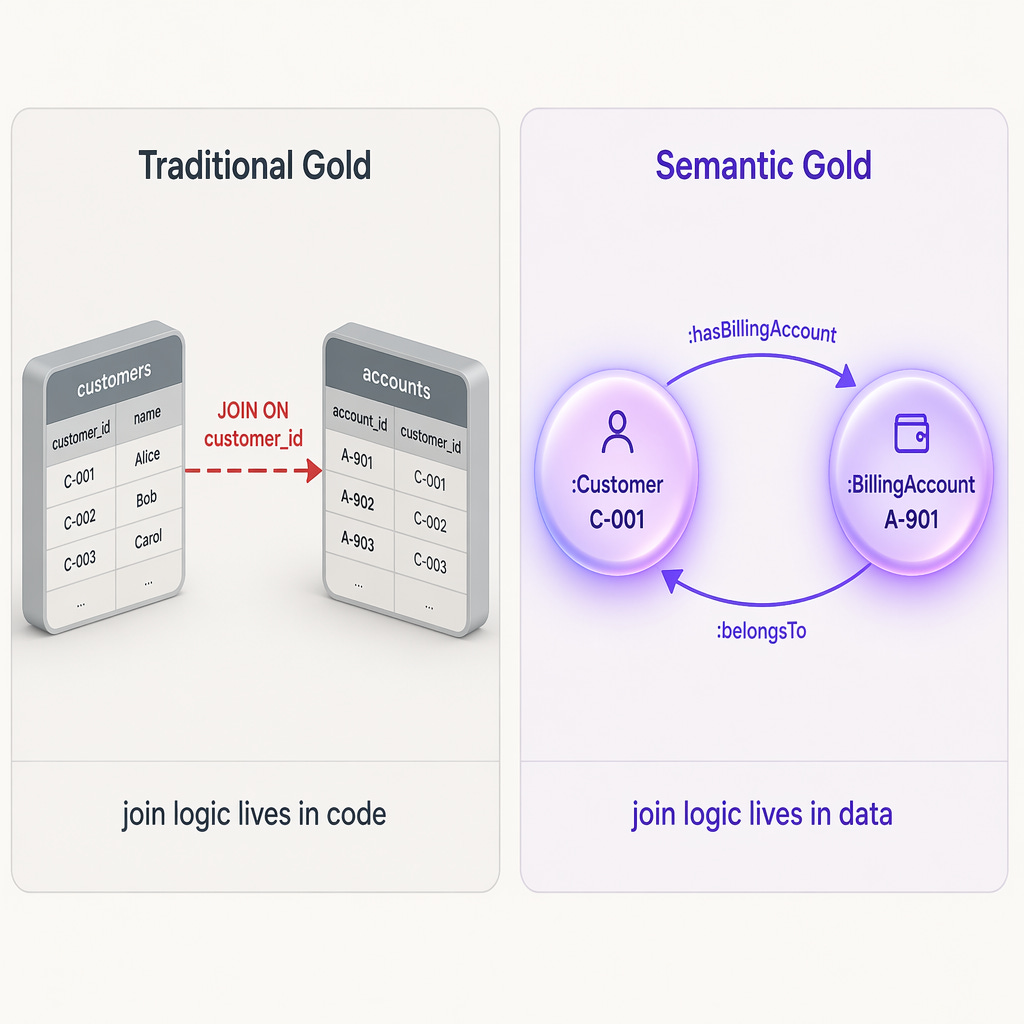
Here is where things change. Not “more tables, better joined.” A metamorphosis. Silver DataFrames are mapped to a shared ontology, a common vocabulary that says what things mean and how they relate, and published as an RDF knowledge graph.
The relationships are no longer maintained in SQL scripts or dbt models. They are in the data. A customer record knows it has a billing account. A contract knows it belongs to a customer. The graph is navigable without joins because the joins are the data.
Same fact in both worlds.
Traditional Gold (Parquet / Delta):

Semantic Gold (RDF / Turtle):
@prefix ex: <https://example.org/> .
@prefix : <https://example.org/ontology/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
ex:customer/C-001
a :Customer ;
:name "Acme Corp" ;
:country "NL" ;
:hasBillingAccount ex:account/A-901 .
ex:account/A-901
a :BillingAccount ;
:balance "1240.00"^^xsd:decimal ;
:belongsTo ex:customer/C-001 .No join. :hasBillingAccount is a fact in the graph. You traverse it:
PREFIX ex: <https://example.org/>
PREFIX : <https://example.org/ontology/>
SELECT ?account ?balance
WHERE {
ex:customer/C-001 :hasBillingAccount ?account .
?account :balance ?balance .
}The difference is small in a two-table example. It compounds quickly. By the time you have eight entities and twenty relationships, the SQL version is a maintenance burden and the RDF version is the same query pattern as before.
The four lines that do the work
DataFrame-to-RDF used to mean dozens of lines of serialization code. Libraries like maplib, a Python library for ontology-driven RDF generation using OTTR templates, collapse it to four.
Step 1. Define an OTTR template (in stOTTR syntax) that maps DataFrame columns to ontology properties:
@prefix : <https://example.org/ontology/> .
@prefix ex: <https://example.org/> .
@prefix ottr:<http://ns.ottr.xyz/0.4/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
ex:CustomerTemplate [
ottr:IRI ?iri ,
xsd:string ?name ,
xsd:string ?country ,
ottr:IRI ?account
] :: {
ottr:Triple(?iri, rdf:type, :Customer) ,
ottr:Triple(?iri, :name, ?name) ,
ottr:Triple(?iri, :country, ?country) ,
ottr:Triple(?iri, :hasBillingAccount, ?account)
} .Step 2. Map and expand:
from maplib import Mapping
m = Mapping() # 1. create the mapping engine
m.read_template("templates/customer.stottr") # 2. load the OTTR template
m.expand("ex:CustomerTemplate", silver_customers)# 3. expand DataFrame -> triples
m.write_ntriples("s3://gold/graph/customers.nt") # 4. serialize the graphThat's it. DataFrame to knowledge graph. The template carries the semantics. The DataFrame carries the data. The library does the boring part.
The executable model
A second approach reaches the same place from the opposite direction. The Semantic Medallion asks what Gold should be. This one asks a different question. How do you stop the physical world from drifting away from the conceptual one?
Every data platform has two universes running in parallel.
The conceptual universe lives in whiteboard photos, Slack threads, and the heads of analysts. “We need to track which platform each course is published on.”
The physical universe lives in Lakehouse tables, notebook code, and ETL pipelines.
Keeping them aligned is nobody’s job, so they drift. Columns get added without documentation. Business concepts get renamed while database schemas fossilize. Three months later, an AI agent hits the mismatch and hallucinates an answer. Someone catches it the following Tuesday. By then, two dashboards have been quietly wrong for weeks.
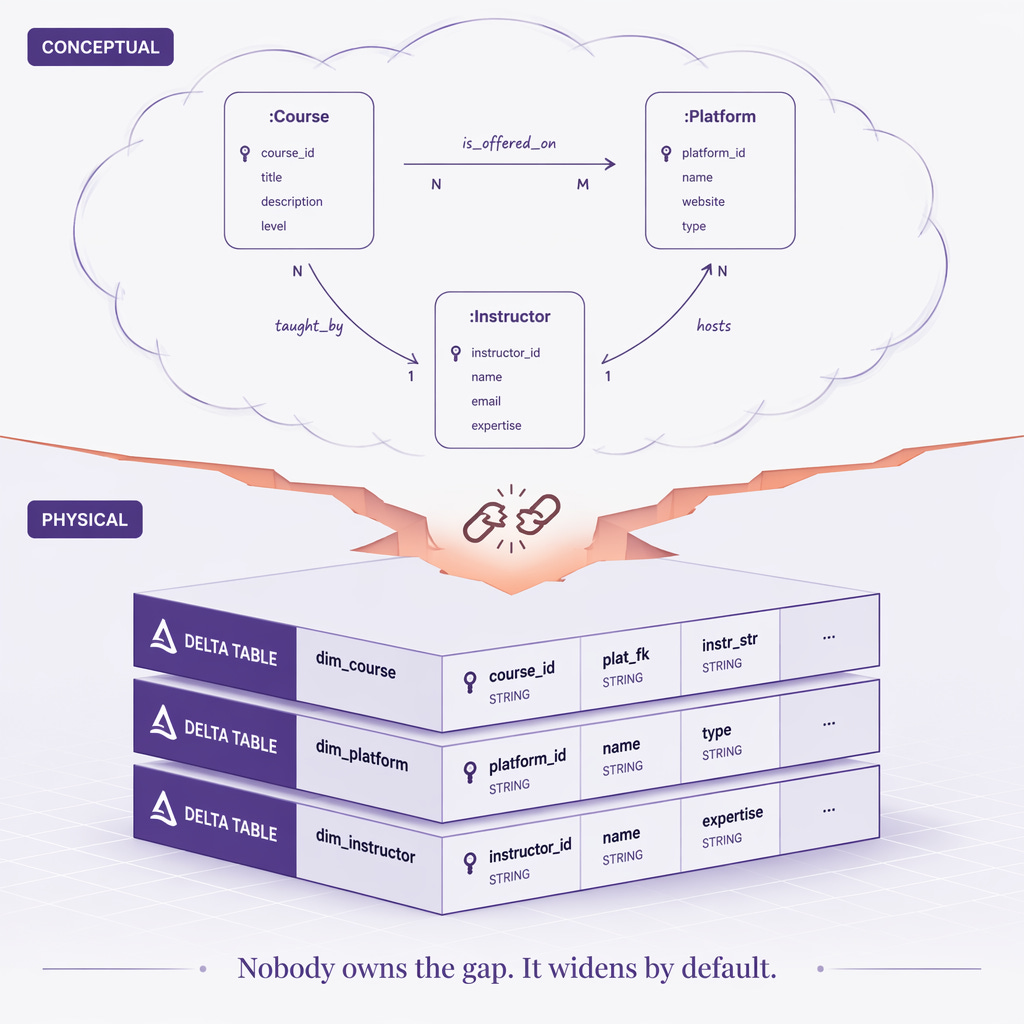
The fix is to make the ontology executable. The ontology stops being a description and starts driving the storage. When it changes, a sync engine diffs the current Lakehouse schema against the desired state, generates the necessary Spark SQL, and applies a consolidated atomic update.
Roughly:
# Pseudocode for an ontology-driven schema sync engine.
from rdflib import Graph
from pyspark.sql import SparkSession
def sync_ontology_to_lakehouse(ontology_path: str, catalog: str):
spark = SparkSession.builder.getOrCreate()
onto = Graph().parse(ontology_path, format="turtle")
# 1. Derive the desired schema from the ontology.
desired = derive_schema_from_ontology(onto) # {class: {prop: xsd_type}}
# 2. Inspect the current Lakehouse schema.
current = introspect_catalog(spark, catalog) # {table: {col: spark_type}}
# 3. Diff and emit DDL.
plan = diff(current, desired)
# plan looks like:
# ADD Course.publishedOn STRING
# ALTER Instructor.email STRING -> STRING NOT NULL
# CREATE TABLE Platform (iri STRING, name STRING, url STRING)
# 4. Apply atomically.
with spark.sql("BEGIN TRANSACTION"):
for stmt in plan.to_sql():
spark.sql(stmt)When a domain expert adds :publishedOn to the :Course class in the ontology, the next sync run figures out that course.published_on STRING is now required, generates the ALTER TABLE, and applies it. The ontology is not a map taped to the warehouse wall. It is the blueprint the warehouse gets built from.
So again. Not a semantic layer above the storage. The semantic definition becoming the storage.
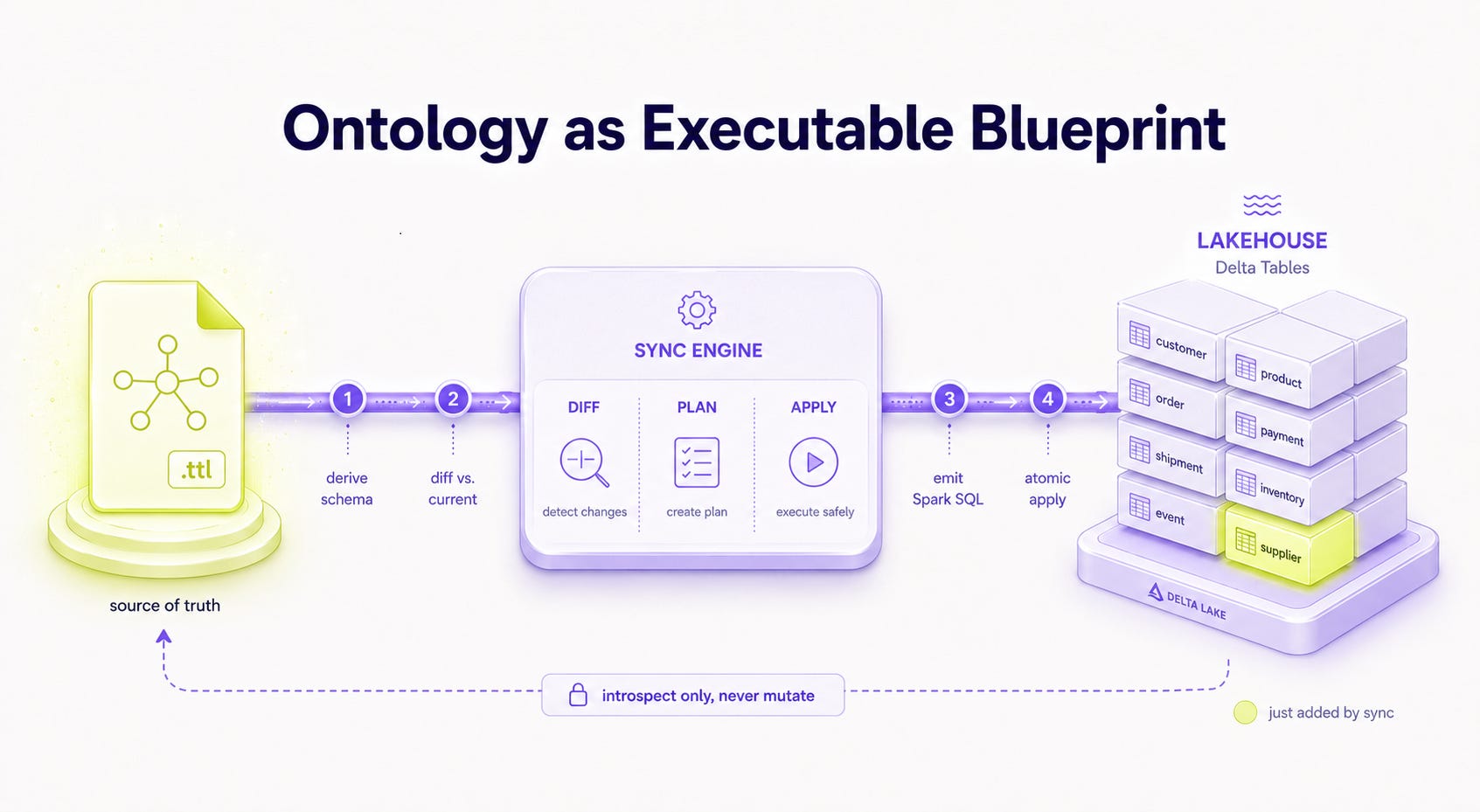
The new count
Back to the room. “Isn’t that too many layers?”
Under the traditional view, the count goes:
Bronze (raw tables)
Silver (clean tables)
Gold (business tables)
Semantic layer (meaning, graphs, ontology)
Consumption (BI, AI, applications)
Five. No wonder it feels heavy.
Under the redesigned view:
Bronze — Harvest and Land (no semantics)
Silver — Structure and Identify (local semantics, IRIs minted)
Gold — Harmonize and Publish as Ontology-Native (global semantics)
Three. Same count we already had. The Gold layer has just changed state. It is no longer “clean data in nice tables.” It is a knowledge graph where every record knows its relationships to every other record across all sources. The semantics are not layered on. They are in.
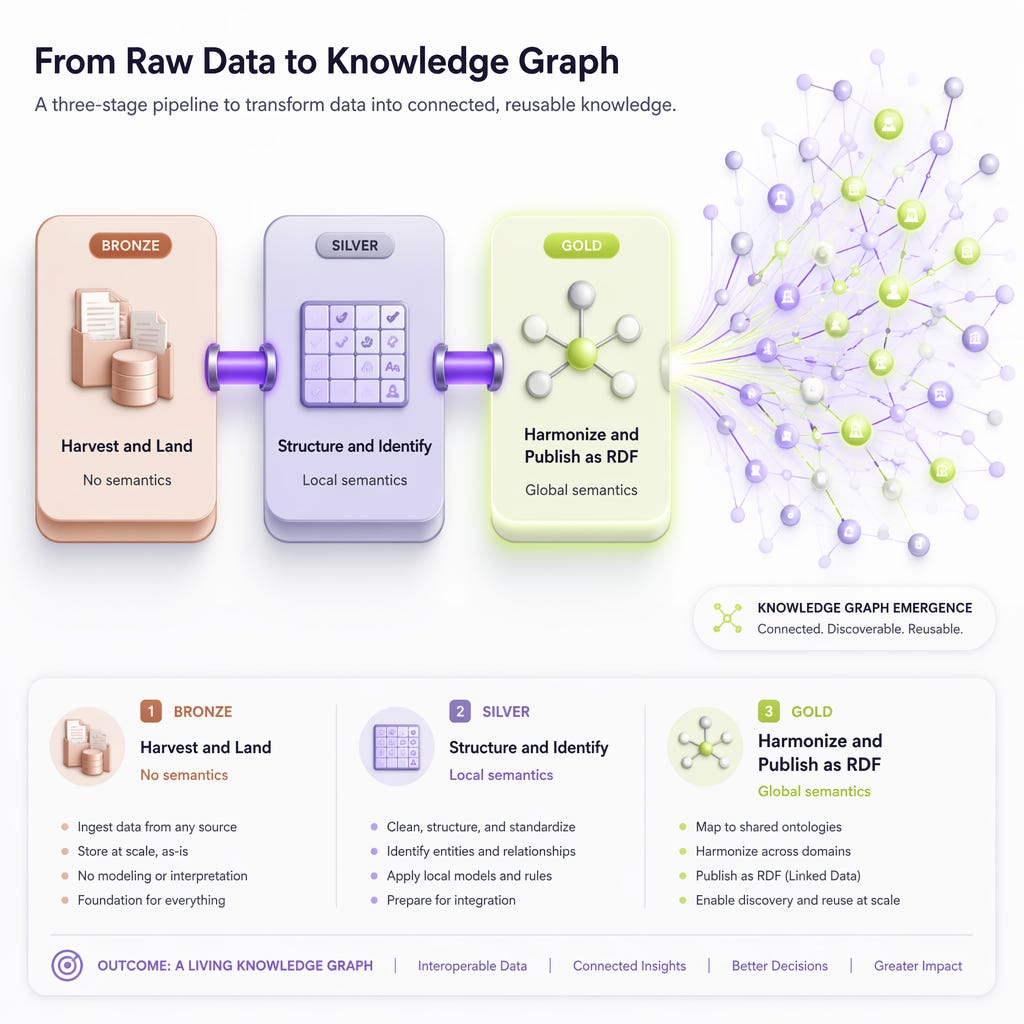
What this means in practice
The day-to-day work changes.
Traditionally, the workflow goes: model the business in a meeting, translate to SQL in a notebook, deploy the tables, write documentation, hope the documentation stays current. The ontology, if it exists at all, is the last thing anyone makes. A metadata catalog that describes what was already built.
The redesigned workflow flips the order. Model the business in the ontology. Let the sync engine generate the schema. Let the pipeline populate the graph (DataFrame → OTTR template → RDF). The ontology is the contract. When the business changes, the ontology changes, and the storage follows.
A concrete example. Say you want to add a :Subscription entity to the customer domain.
# In the ontology — one commit.
:Subscription
a owl:Class ;
rdfs:label "Subscription" ;
rdfs:subClassOf :Agreement .
:hasSubscription
a owl:ObjectProperty ;
rdfs:domain :Customer ;
rdfs:range :Subscription .That single change cascades. The sync engine creates a subscription Delta table with the right columns. An OTTR template gets registered for :Subscription. The catalog lists the new dataset with a SPARQL endpoint. You didn’t write a migration script and you didn’t have to call a meeting.
This does not eliminate ETL. Data still has to move from somewhere to somewhere. But the “T” stops being “translate to tables and keep the join logic alive” and becomes “transform into meaning.” Schema evolution is derived from the ontology instead of hand-coded in migration scripts.
The catalog you get for free
Once Gold is RDF, you get a catalog that is part of the same graph as the data it describes. Almost as a side effect.
You don’t need a custom schema for describing your datasets. The W3C standard DCAT (Data Catalog Vocabulary) exists for this. A DCAT description of the Gold graph looks like:
@prefix dcat: <http://www.w3.org/ns/dcat#> .
@prefix dct: <http://purl.org/dc/terms/> .
@prefix ex: <https://example.org/> .
ex:catalog/main
a dcat:Catalog ;
dct:title "Enterprise Knowledge Graph" ;
dct:publisher ex:org/data-platform ;
dcat:dataset ex:dataset/customers, ex:dataset/billing .
ex:dataset/customers
a dcat:Dataset ;
dct:title "Customer 360" ;
dct:description "Unified customers across CRM, billing, external registry." ;
dcat:distribution ex:dist/customers-sparql .
ex:dist/customers-sparql
a dcat:DataService ;
dcat:endpointURL <https://example.org/sparql> ;
dct:format "application/sparql-results+json" .Catalog and data live in the same graph. Same endpoint. Same query language. Provenance comes along for free if you layer in PROV-O. Lineage stops being a separate tool with its own database and becomes queryable triples.
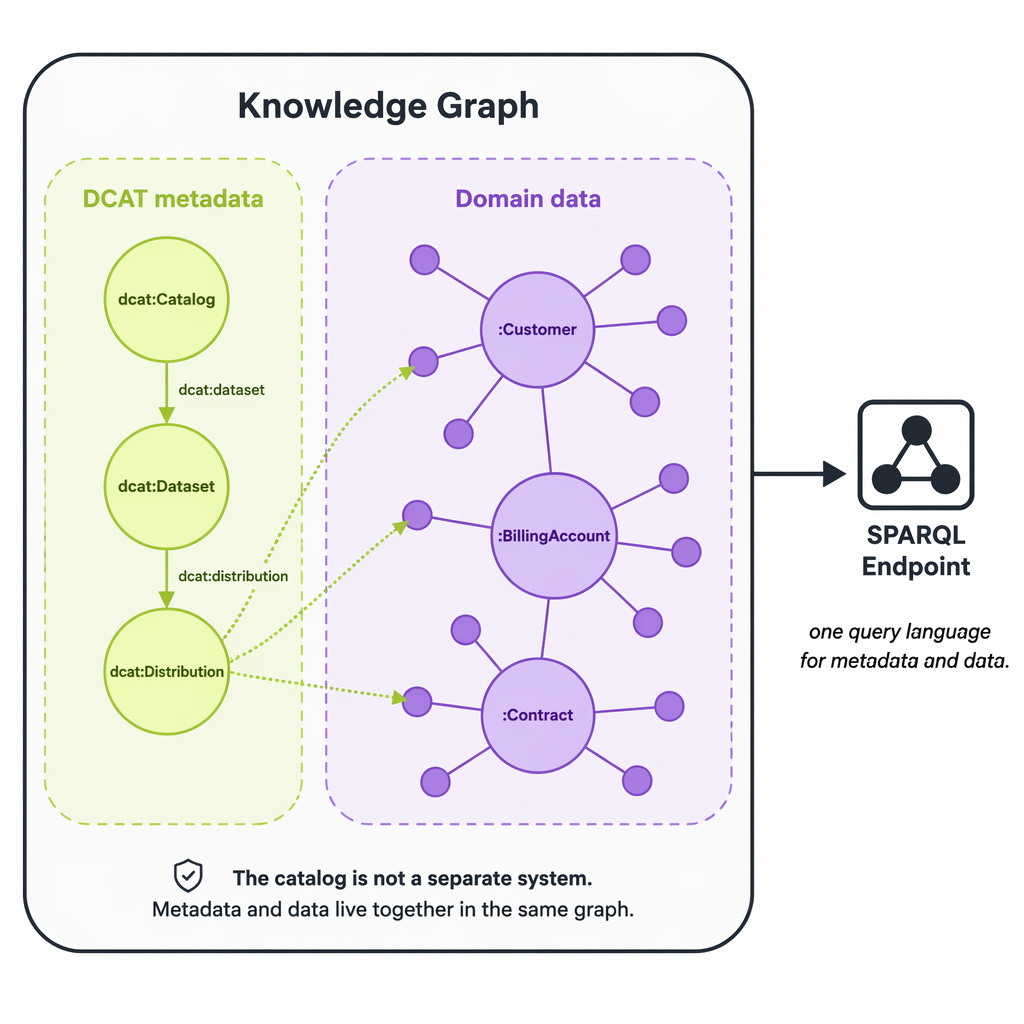
The caveats
No architecture is free. This one has sharp edges and it would be dishonest to skip them.
It’s a design-time revolution, not a runtime one. The ontology-driven sync makes it trivial to iterate on schema in development. Twenty designs in an afternoon, each one rebuilding the tables automatically. In production, data still flows through pipelines and capacity still costs money. Destructive changes (DROP COLUMN, ALTER TYPE) still need governance, migration windows, and a rollback plan. Your sync engine should refuse destructive operations without an explicit --allow-breaking flag. If it doesn’t, you will eventually drop a column on a Friday afternoon and your weekend will be ruined.
The ontology is only as good as the discipline to maintain it. If engineers can add columns directly to tables in a notebook, bypassing the ontology, the two worlds will drift apart again. The whole thing needs organizational buy-in: the ontology is the source of truth, full stop. A simple guardrail is a CI check that fails if introspection finds columns that aren’t derivable from the ontology:
$ ontology-sync check --catalog gold --ontology onto/main.ttl
✗ silver.customer.legacy_segment — not present in ontology
✗ gold.subscription.notes — not present in ontology
Exit code: 1Not every dataset needs to be a knowledge graph. A log of temperature readings is a log. A time series is a time series. The semantic upgrade pays off when the business question is “how does this connect to that?” Less so when it’s “what was the value at 3 PM?” A rule of thumb I use: if you are maintaining more than three or four cross-domain joins in dbt, you have a graph-shaped problem and Gold-as-RDF is worth trying for that domain. If you are computing windowed aggregations over event streams, stay in tables.
SPARQL is a real skill investment. Your analysts know SQL. You either train them or wrap the graph behind a SQL-on-RDF layer like Ontop or R2RML for legacy BI tools, which adds back some of the complexity you were trying to remove. Plan for it.
Back to the room
I wish I had had this answer when the hand went up. The semantic layer is not too many layers because it is not a layer. It is the state Gold reaches when it stops being raw material and starts being a system that knows itself.
We are not stacking pancakes. Gold doesn’t get more valuable by getting thicker. It gets more valuable by understanding what it is.
Try it yourself
If you want to prototype this on a Monday:
Pick two source systems that describe overlapping entities. CRM and billing is the classic starter pair.
Mint IRIs in Silver. Pattern:
https://<your-org>.example/<entity>/<stable-id>. Stability matters more than elegance.Write a minimal ontology. Five to ten classes, twenty properties. Use
rdfs:labelandrdfs:commentgenerously.Use maplib or Morph-KGC to expand DataFrames into RDF via OTTR or R2RML templates.
Load into a triplestore (GraphDB, Fuseki, Stardog) and run your first SPARQL query.
Describe the catalog with DCAT, even just three triples, and see what it feels like to query metadata and data in one language.
You already have Bronze and Silver. Now let Gold change state.